ifia JAPAN 2024会場で頂戴したご質問への回答まとめ
食品事業部の村瀬です。
弊社は、2024.5.22(水)~24(金)、東京ビッグサイトにて開催された
「ifia JAPAN 2024 第29回 国際食品素材/添加物展・会議」
(食品化学新聞社主催)に出展いたしました。
展示ブースにお越しいただいた皆様、誠にありがとうございました。
この記事では、展示期間中、皆様から頂戴したご質問の中から
特に多くいただいた内容をご紹介し、回答いたします。
ぜひ最後までご覧ください。
Q:何ができる会社ですか?
A:お客様のご要望に応じて、新規酵素探索、酵素改変を行います。
従来の手法とは異なる、独自のバイオインフォマティクス技術を用いた
スピーディーな酵素開発によって、酵素メーカー、食品メーカー両者にとっての
イノベーションアクセラレーターになることができると考えています。
Q:具体事例はありますか?
A:ケミカル用途では、ユーザーが必要とする新規酵素の探索や、
酵素の大幅な活性向上に成功した事例がございます。
食品用途では、現在複数のお客様より具体的なテーマをいただき
実際にお取り組みさせていただいている状況です。

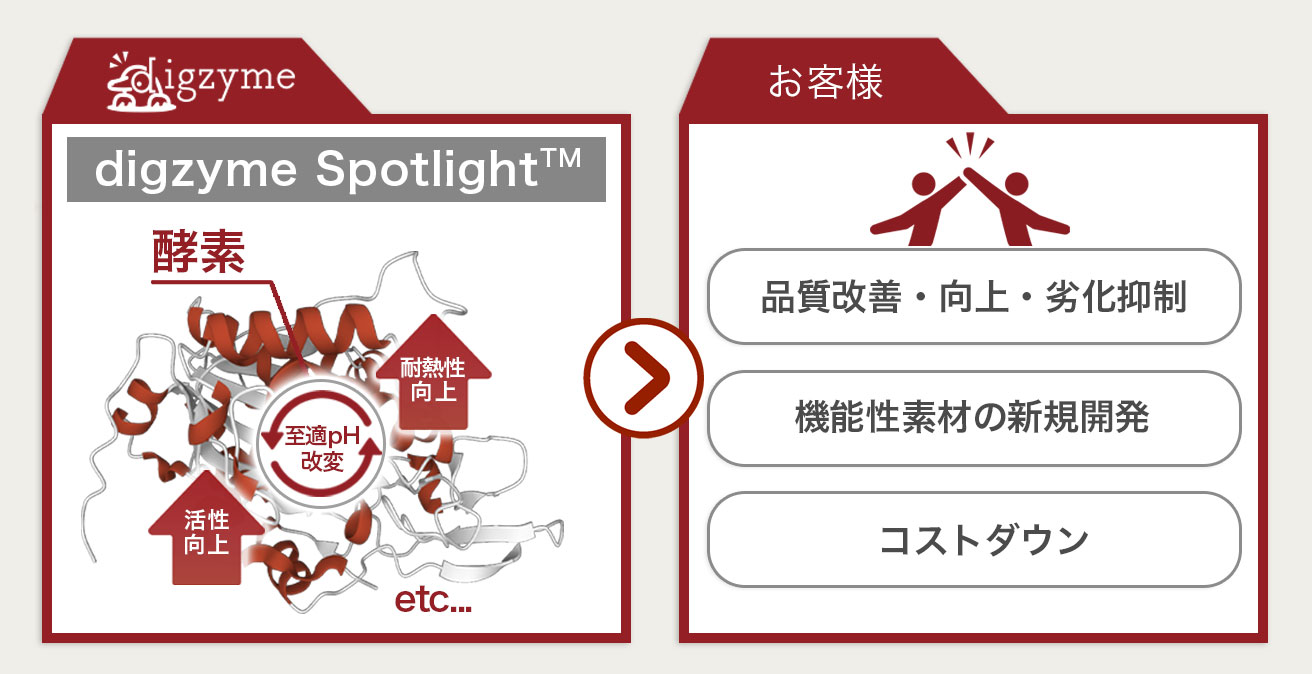
Q:digzyme Spotlight(酵素改変型プログラム)では、酵素の何の性質が改変できる?
A:活性向上、耐熱性向上、至適pHの改変などが考えられます。
基質特異性の改変は状況に応じて、digzyme Moonlight(酵素探索型プログラム)を使用します。
Q:どのような流れで開発を進める?
A:お客様の状況に応じて、スタートとゴールを設定させていただきますが
主な流れは以下となります。
1.開発コンサルティング:お客様の課題をヒアリングし、ターゲットとする酵素を選定します。
2.酵素デザイン:スーパーコンピューターを用いて、ターゲットとなる酵素のデザインをします。
3.酵素ライブラリ提供:コンピューター上でデザインした酵素を
実際に微生物を用いてラボスケールで製造し、目的に沿った酵素かを検証・確認します。
4.酵素の生産提供:製造スケールをラボからプラントへスケールアップし、
製品として酵素を安定供給できる体制を整備します。
当記事でのQ &Aは以上です。
それでは、最後までご覧いただきありがとうございました。
その他のご質問などございましたら、下記のコンタクトフォームよりお問い合わせくださいませ。
【▼コンタクトフォーム】
https://www.digzyme.com/contact/
Spotlightによる酵素変異体の活性予測精度を先行研究と比較
はじめに
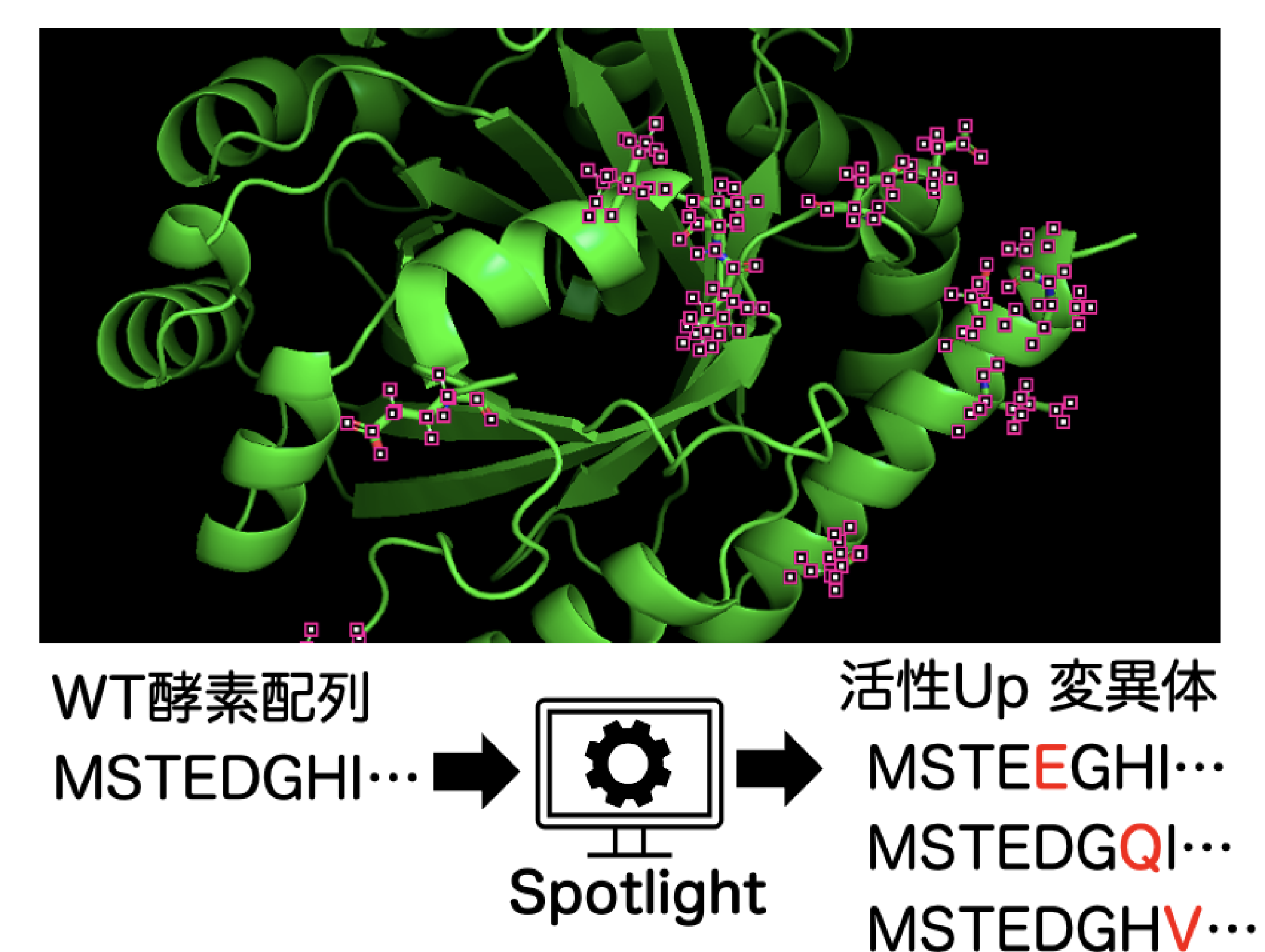
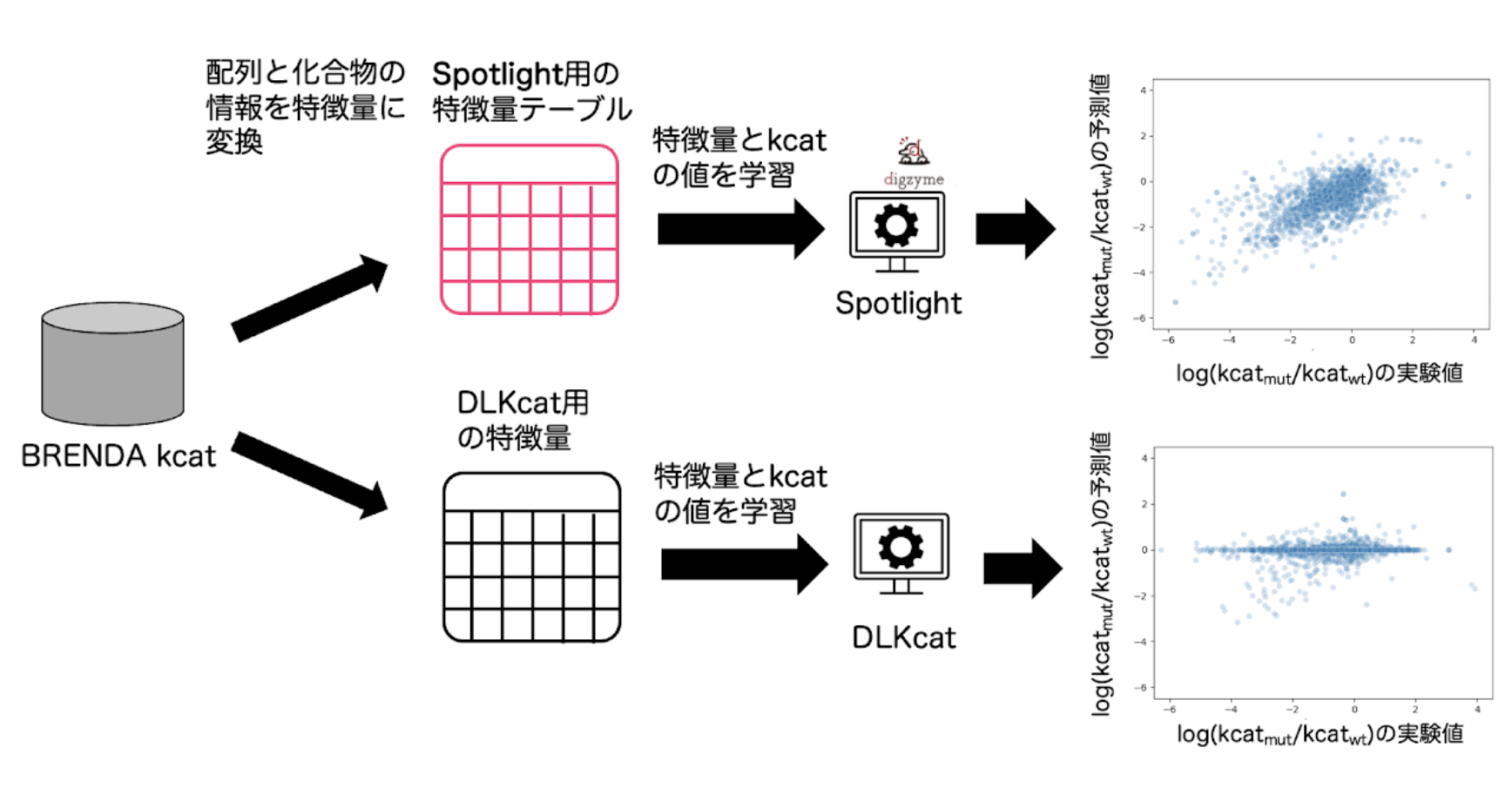
事業開発部の礒崎です。弊社では酵素の活性や耐熱性などのプロパティを向上させる変異体を機械学習モデルを用いて提案するSpotlightというサービスを提供しています。様々な酵素を使って学習済みのモデルに、社内または社外から依頼を受けた目的の配列をインプットすることで活性などが向上する変異体を予測します。今回のtechblogではこのSpotlightの変異体の活性予測精度が先行研究と比較してどの程度なのか検証しました。
比較対象に使用した先行研究
Li et al., 2022では、酵素のアミノ酸配列と化合物を入力情報としてkcatを予測する機械学習モデルを構築していました。今回の比較ではこの機械学習モデルアルゴリズム(DLKcat)を用い、かつ、比較を平等にするためにSpotlightと同じ教師データであるBRENDAのkcat エントリーを使ってモデルを再構築しました。この再構築したDLKcatにより予測した変異体のkcatの値とSpotlightで予測したkcatの値のいずれが実測値とより近いか比較しました。今回使用したBRENDAのエントリーにはwild type (WT) と単変異体のみが含まれるように抽出し、変異1つに対する感度が2つのモデルでどれくらい違うかに注目して比較しました。
結果
1. BRENDAのkcat (=Turnover Number)のデータを用いた学習モデルの構築
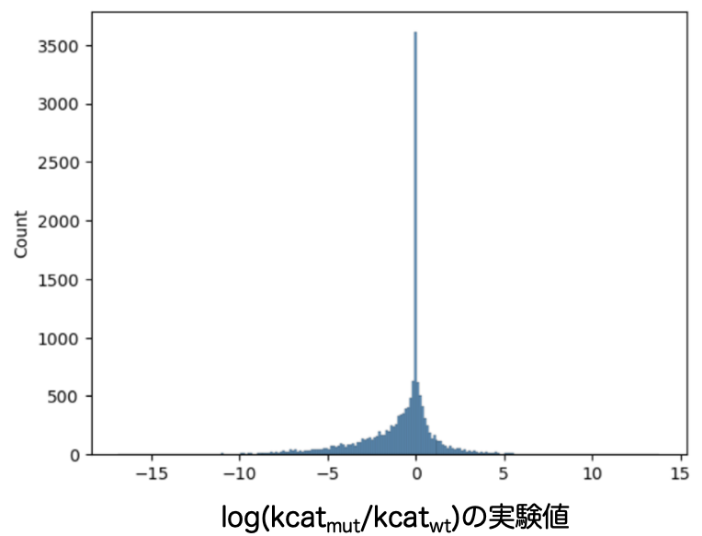
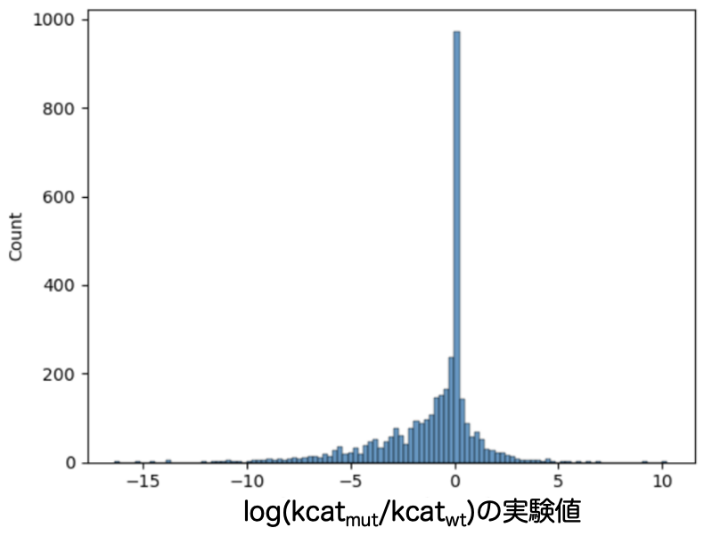
BRENDAのkcatが記載されている変異体、そのWTの配列のエントリーおよびkcatを測定した化合物の情報を抽出し、これらを酵素ファミリーに偏りが生じないように、かつ、およそ教師データ:テストデータ= 3 : 1になるように分割しました。分割後の教師データではkcatが向上しているエントリーが3969、変化しないエントリーが2985、減少しているエントリーが8296でした(図1)。分割後のテストデータではkcatが向上しているエントリーが792、変化しないエントリーが748、減少しているエントリーが1926でした(図2)。
2. DLKcat・Spotlightで予測したkcatの変異体/WT比率の評価
抽出したBRENDAのエントリーの情報をDLKcatが要求する特徴量の形に変換し、教師データの中のkcatの実験値と合わせて学習モデルを構築しました。Spotlightでも同様にこれらのエントリーをSpotlightが要求する特徴量の形に変換して、kcatの実験値と合わせて学習モデルを構築しました(図3)。
DLKcatで予測した変異体のkcatとWTのkcatの比率は実測値と予測値の間でピアソン相関係数が0.18でした(図3)。DLKcatにおいて予測した変異体とWTのkcatの比率が実測値と良く相関しなかった理由は、DLKcatでは特徴量として配列の全長をベクトルに変換しているため1アミノ酸の違いが特徴量に現れづらくなっているからであると考えています。Spotlightで予測した変異体のkcatとWTのkcatの比率は実測値と予測値の間でピアソン相関係数が0.66でした(図3)。弊社のSpotlightでは特徴量に変異体としての性質を大きく反映できる工夫をしてあるため、単変異体のエントリーであってもWTからの1変異による変化を正確に予測することができています。
終わりに
弊社のSpotlight™では先行研究と比べて、単変異体というWTから1アミノ酸しか違わないようなケースでも、その変化を正確に反映してより実験値に近い値を予測可能であるということが明らかになりました。
謝辞
今回の酵素活性予測の精度比較には以下の論文のデータを利用させていただきました。
Li et al., (2022) Deep learning-based kcat prediction enables improved enzyme-constrained model reconstruction. Nature Catalysis.